
Ontopavese
Ontologia
OntoPavese in breve
L’ontologia formale OntoPavese ambisce a rappresentare l’opera di Cesare Pavese in ampiezza e profondità, strutturando in una gerarchia semantica rigorosa la conoscenza disponibile. Vi trovano spazio tutte le opere edite, poetiche e in prosa, oltre alle carte private, come le lettere e il diario, e dati d’archivio. Si compone così un tessuto coerente di informazioni bibliografiche, filologiche ed archivistiche, allineato da un lato al modello LRM (Library Reference Model) dell’IFLA e alla relativa ontologia formale, LRMoo, ormai incorporata in quella di CIDOC-CRM; dall’altro, al modello RiC (Records in Context) elaborato dall’ICA, e alla sua ontologia, RiC-O.
Attualmente, il popolamento comprende la bibliografia primaria delle opere scritte da Pavese completa, con le riedizioni delle principali. Delle opere più rilevanti sono presenti le informazioni relative alle singole poesie, capitoli, dialoghi, con informazioni su lingua, traduzioni, sezioni, pagine, date di creazione e collegamenti alle pagine dell’edizione digitale commentata di Pavese In Testo.
Sono, inoltre, modellati lettere, pagine di diario e saggi, dati estratti dalle codifiche in XML-TEI, allo stato attuale del progetto (febbraio 2026), con dati su autore, opera di riferimento, lingua, luogo, intervalli temporali di creazione, mittente e destinatario.
Completano il quadro i dati archivistici sulle stesure manoscritte delle poesie di Lavorare Stanca ‘36, relativi a segnature, collocazione e versioni.
Con OntoPavese non solo si rendono disponibili i dati, ma si possono interrogare, tramite uno strumento di ricerca capace di far emergere nuove connessioni e nuove domande.
Cos'è un'ontologia formale?
L’ontologia OntoPavese è il cuore concettuale del portale PAVES-e: un modello che organizza e collega tra loro tutte le informazioni sulle opere di Pavese, sulla loro genesi e sulle risorse d’archivio che le conservano. Il suo obiettivo non è solo rendere disponibili i dati e permettere di interrogarli, ma offrire uno strumento di ricerca dinamico, capace di far emergere nuove connessioni e nuove domande.
Per capire in che modo OntoPavese consenta tutto questo, occorre chiarire cosa si intende per ontologia formale. Nel dominio dell’informatica, questo termine indica una rappresentazione di un certo ambito della conoscenza (nel nostro caso, l’opera di Pavese) attraverso le entità che ne fanno parte, con le loro caratteristiche e le relazioni che le legano. Più precisamente, un’ontologia permette di definire la tipologia di un oggetto (la classe a cui appartiene) e le sue proprietà. Per esempio, tra i tipi di entità che potrebbero essere utili per OntoPavese ci sono le case editrici, così come i libri che pubblicano: definiremo dunque queste due classi. E poiché ciò di cui si occupa una casa editrice è appunto pubblicare libri, diremo che “pubblicare” è una proprietà associata a questo tipo di entità.
Quando questo schema viene riempito (tecnicamente si dice “popolato”) con i dati che riguardano le entità particolari che vogliamo descrivere (per esempio, le edizioni delle opere pavesiane), si ottiene un grafo di conoscenza: una rete in cui ogni elemento è connesso ad altri attraverso delle relazioni. In un grafo di conoscenza tutte le informazioni hanno la forma di una tripletta: soggetto, predicato e oggetto.
Nell’immagine di seguito, abbiamo una rappresentazione dell’ontologia elementare appena descritta, con la classe delle case editrici e quella dei libri collegate attraverso la proprietà “pubblica”.

L’ontologia è dunque solo una struttura vuota. Quando la popoliamo, quando cioè assegniamo a certi oggetti una determinata classe, otteniamo un grafo di conoscenza. Possiamo per esempio inserire “Einaudi”, un’entità che appartiene alla classe delle case editrici, e “Lavorare stanca”, un libro di Pavese pubblicato appunto da questo editore. Il grafo che ne risulta è mostrato nell’immagine seguente, e mette in evidenza il modello soggetto-predicato-oggetto già descritto.

Tanto il soggetto (“Einaudi”) quanto l’oggetto (“Lavorare stanca”) possono poi essere coinvolti in altre triplette, in una vasta rete di relazioni: una proprietà “ha sede”, per esempio, potrebbe indicare che Einaudi ha sede a Torino, per la quale occorrerebbe definire una classe come “Luoghi”.
Ma perché utilizzare una rappresentazione di questo tipo, invece di un più classico database sql organizzato in righe e colonne, come questo?
| Editore | Libro |
|---|---|
| Einaudi | Lavorare Stanca |
La risposta è che un’ontologia offre numerosi vantaggi; per citarne solo alcuni:
- Può essere integrata facilmente con nuove informazioni. Per esempio, se in futuro volessimo rappresentare i film basati su un certo libro, sarà sufficiente aggiungere una classe “Film” e una proprietà “è basato su”. Nei database sql le informazioni delle varie tabelle sono collegate attraverso relazioni che rendono molto oneroso aggiungere nuove caratteristiche (nuove colonne) al modello, una volta che questo è stato definito.
- Gestisce con semplicità l’informazione incompleta. Se di una certa casa editrice non è nota la sede, basta non inserirla. In un database sql, una cella vuota comporta delle difficoltà nel trattamento dei dati.
- Permette di dedurre informazioni implicite. Le ontologie usano algoritmi detti “motori inferenziali” che consentono, definendo delle regole, di scoprire nuovi dati impliciti in quelli che abbiamo. Se si stabilisce la regola che chi pubblica libri è sempre e solo una casa editrice, una volta inserita l’informazione che “Einaudi pubblica Lavorare stanca” e attribuita a Lavorare stanca la classe Libro, non occorre dichiarare esplicitamente che Einaudi appartiene alla classe Casa Editrice: questa informazione viene dedotta automaticamente grazie alla regola.
Al di là di queste caratteristiche operative, però, la caratteristica più importante delle ontologie è legata alla possibilità che offrono di fare rete con altre informazioni già esistenti, di contribuire così alla cosiddetta Scienza Aperta.
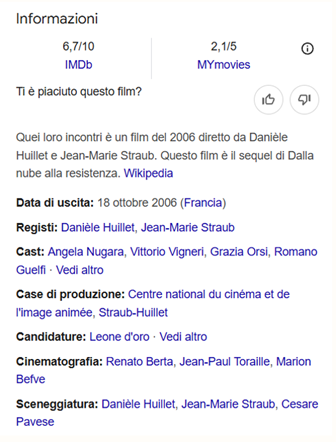
Infatti, ogni entità di un’ontologia è associata in modo univoco a un indirizzo su internet (un URI, Uniform Resource Identifier). Questa caratteristica, insieme al fatto di fare riferimento ad altre ontologie che sono standard nell’ambito di nostro interesse (che è quello dei beni culturali, degli archivi e delle risorse letterarie) permette di inserire la nostra ontologia in una più ampia rete di informazioni già esistente, il Web Semantico, che comprende, per citarne solo pochissimi, i dati di Wikipedia, del Progetto Gutenberg, dell’Internet Movie Database, della Camera dei Deputati italiana. Per fare un esempio delle possibili applicazioni del Web Semantico, è proprio grazie a questi cosiddetti Linked Open Data che, quando utilizziamo un motore di ricerca, spesso in risposta alla nostra interrogazione visualizziamo un pannello riassuntivo di informazioni, raccolte da fonti come quelle appena menzionate. Qui di seguito riportiamo il knowledge panel che viene visualizzato cercando su un motore di ricerca “Quei loro incontri”, un film ispirato ai Dialoghi con Leucò di Pavese.
L’immagine seguente rappresenta la Linked Open Data Cloud, ovvero la visualizzazione grafica dell’ecosistema dei dataset pubblicati secondo i principi dei Linked Data.
Grazie all’integrazione con i Linked Open Data resa possibile dalla sua ontologia, il portale PAVES-e dunque non solo rende disponibili le proprie informazioni alla collettività, ma può collegarle a repertori esterni, per trarne dati su biografie, luoghi, eventi storici, ecc. Questo significa che quando interroghiamo OntoPavese con domande complesse – come “A quali opere lavorava Pavese nel giugno del 1935?” oppure “A chi scrive più spesso durante il confino?” – è possibile ottenere risultati più articolati, arricchiti da tutti dati reperibili sul web.
In altre parole, l’ontologia non è soltanto uno strumento tecnico per organizzare dati, ma un’infrastruttura concettuale che rende l’informazione connessa, espandibile e riusabile nel tempo. È questa capacità di mettere in relazione livelli diversi – testi, documenti, persone, luoghi, eventi – e di integrarli con risorse esterne che trasforma un semplice archivio digitale in un vero ambiente di ricerca.
OntoPavese è, in definitiva, una mappa digitale dell’universo di Pavese: una struttura invisibile ma fondamentale, che trasforma un patrimonio di documenti e studi in una rete di conoscenza esplorabile, interrogabile e in continua evoluzione.
Documentazione di OntoPavese
[Presto disponibile]
Esempi di query in OntoPavese
Come visualizzare OntoPavese in GraphDB
