Ontopavese
The Ontology
OntoPavese in a nutshell
The formal ontology OntoPavese aims to represent the works of Cesare Pavese in both breadth and depth by structuring the available knowledge within a rigorous semantic hierarchy. It encompasses all published works, both poetry and prose, as well as private documents such as letters and diaries, and archival data. In this way, it builds a coherent network of bibliographic, philological, and archival information aligned, on one side, with the IFLA Library Reference Model (LRM) and its related formal ontology, LRMoo, now incorporated into CIDOC-CRM, and, on the other side, with the Records in Contexts (RiC) model developed by the ICA and its ontology, RiC-O.
At present, the dataset includes the complete primary bibliography of works written by Pavese, along with the major re-editions. For the most significant works, information is available on individual poems, chapters, and dialogues, including details on language, translations, sections, pages, dates of creation, and links to the digital annotated edition of Pavese In Testo.
Letters, diary pages, and essays are also modeled based on data extracted from XML-TEI encodings, in their current project state (February 2026), with metadata on author, related work, language, place, creation time spans, sender, and recipient.
Completing the framework are archival data concerning the handwritten drafts of the poems from Lavorare Stanca (1936), including signatures, location, and versions.
OntoPavese not only makes this data accessible but also enables researchers to query it through a search tool designed to reveal new connections and inspire new questions.
What is a formal ontology?
OntoPavese is the conceptual core of the PAVES-e portal: a model that organises and interconnects all information relating to Pavese’s works, their genesis, and the archival resources in which they are preserved. Its purpose goes beyond simply making data available and queryable — it aims to provide a dynamic research tool capable of surfacing new connections and generating new scholarly questions.
To understand how OntoPavese achieves this, it is necessary to clarify what is meant by a formal ontology. In the field of computer science, the term refers to a structured representation of a given domain of knowledge — in our case, Pavese’s literary output — through the entities that constitute it, their characteristics, and the relationships that bind them together. More precisely, the goal is to define both the type of a given object (the class to which it belongs) and its properties. For example, among the entities most relevant to our purposes are publishing houses and the books they produce: we therefore define these as two distinct classes. And since the defining activity of a publishing house is, precisely, to publish books, we specify that “to publish” is a property associated with this type of entity.
When this abstract schema is filled — or, in technical terms, populated — with data describing the specific entities we wish to represent (such as the various editions of Pavese’s works), the result is a knowledge graph: a network in which every piece of information is connected to others through explicit relationships. In both an ontology and a knowledge graph, all information takes the form of a triple: subject, predicate, and object.
The image below offers a visual representation of the elementary ontology described above, in which the class of publishing houses and the class of books are linked through the property “publishes.”

As we noted, an ontology is by itself nothing more than an empty structure. When we populate it with actual data — that is, when we assign real-world objects to their respective classes — the result is a knowledge graph. For instance, “Einaudi” is an entity belonging to the class of publishing houses, and Lavorare stanca is a book by Pavese published by that very house. The resulting graph is illustrated in the image below, and clearly exemplifies the subject–predicate–object model described earlier.

Why use this kind of representation rather than a more conventional SQL database organised in rows and columns?
| Editore | Libro |
|---|---|
| Einaudi | Lavorare Stanca |
The answer is that an ontology offers a number of significant advantages. We highlight just a few:
a) It can be easily extended with new information. If we decide to represent the author of a book, it suffices to add an “author” class and a “wrote” property. In SQL databases, the various tables are connected through fixed relational structures, which makes adding new attributes — new columns — a costly and complex operation.
b) It handles incomplete information gracefully. If the author of a given book is unknown, we simply omit that piece of data. In a SQL database, an empty cell introduces non-trivial complications in data processing.
c) It enables the inference of implicit information. Ontologies can be paired with algorithms known as inference engines, which apply user-defined rules to derive new knowledge from existing data. For example, if we establish the rule that any entity that publishes books is a publishing house, then once we record that “Einaudi publishes Lavorare stanca” and classify Lavorare stanca as a Book, we do not need to explicitly declare that Einaudi is a publishing house — this fact is inferred automatically by the engine.
Beyond these operational features, however, the most significant advantage of ontologies lies in their capacity to connect with other existing bodies of information, thereby contributing to what is broadly known as Open Science.
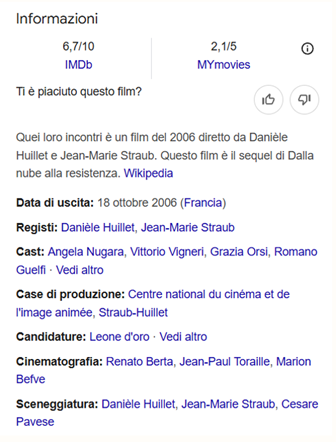
Every entity within an ontology is uniquely associated with a web address — a URI, or Uniform Resource Identifier. This feature, combined with the practice of aligning one’s ontology with established standards in the relevant domain (in our case, cultural heritage, archival studies, and literary resources), makes it possible to integrate the ontology into a much larger pre-existing network of knowledge: the Semantic Web. Among its many contributors are, to name only a few, Wikipedia, Project Gutenberg, the Internet Movie Database, and the Italian Chamber of Deputies. One practical illustration of what the Semantic Web enables: it is precisely through these so-called Linked Open Data that search engines are often able to display a concise summary panel in response to a query, aggregating information from multiple authoritative sources. Below, we reproduce the knowledge panel returned by a search engine for Quei loro incontri, a film inspired by Pavese’s Dialoghi con Leucò.
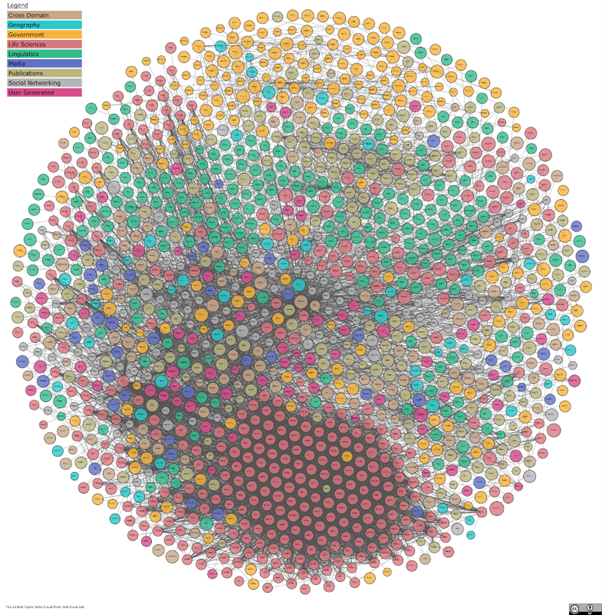
The image below shows the Linked Open Data Cloud — a visual representation of the broader ecosystem of datasets published in accordance with Linked Data principles.
Thanks to the integration with Linked Open Data made possible by its ontology, the PAVES-e portal does not merely make its own information publicly available: it actively connects that information to external repositories, drawing on them for data relating to biographies, places, historical events, and much more. This means that when we query OntoPavese with complex research questions — such as “Which works was Pavese engaged with in June 1935?” or “To whom did he write most frequently during his period of political exile?” — the results we obtain are richer and more layered, enriched by all the relevant data retrievable across the web.
In other words, the ontology is not merely a technical instrument for organising data: it is a conceptual infrastructure that renders information connected, expandable, and reusable over time. It is precisely this capacity to bring together different levels of knowledge — texts, documents, people, places, events — and to integrate them with external resources that transforms a simple digital archive into a fully fledged research environment.
OntoPavese is, in the final analysis, a digital map of Pavese’s universe: an invisible yet foundational structure that turns a heritage of documents and scholarship into a network of knowledge — one that can be explored, interrogated, and continuously expanded.
OntoPavese's documentation
[Coming soon…]
Examples of queries in OntoPavese
How to visualize OntoPavese in GraphDB