The project
About
PAVES-e is the hyperedition dedicated to the author of Lavorare Stanca and La luna e i falò: an integrated digital space where texts and documents engage in a dynamic, meaningful dialogue aimed at a wide audience of readers, students, scholars, and literary enthusiasts.
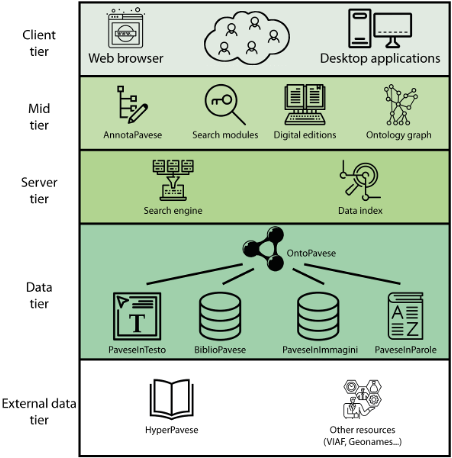
The project seeks to develop an edition that, in line with the FAIR principles (Findable, Accessible, Interoperable, Reusable), (a) builds an innovative interface and (b) integrates, through a robust ontology, lexicographical (e), philological (c, d), critical (g), and educational (f) dimensions. PAVES-e includes:
the design and development of an intuitive, user-friendly web interface (DigitalPavese);
the organization of information and the integration of resources to develop an ontology of places, people, characters, organizations, and works that are central to Pavese’s legacy (OntoPavese);
the creation of a digital archive—complete with descriptions and metadata—of images of autograph manuscripts, typescripts, and first editions (PaveseInImages);
the preparation of scholarly digital editions of the novels, poetry, letters, and diary, encoded in XML-TEI and lemmatized for the literary works (PaveseInText);
the development of a vocabulary and corresponding query software that includes the lemmata from Pavese’s main works (PaveseInWords);
the implementation or adaptation of an XML-TEI annotation tool to facilitate the reuse of texts in educational contexts (AnnotatePavese);
the compilation of a structured, indexed, and interoperable bibliographic archive of secondary literature on Pavese (BiblioPavese).
Semantic modeling
The semantic organization of knowledge within the Pavese domain is designed and structured by means of a computational ontology, named OntoPavese. Ontologies represent the ideal digital tool for managing semantic heterogeneity—provided that the underlying data have been properly cataloged, archived, and enriched with metadata.
To enable integration and overcome the challenges posed by the high variability of heterogeneous data, it is essential to standardize processes by applying metadata standards. Specifically, the ontology schema is formalized using the OWL language (developed by the W3C), relying on the logical-deductive framework of SROIQ description logic, which underpins OWL. OWL is a sufficiently expressive and powerful formal language that allows software applications to interact autonomously, enabling effective automated information processing while supporting structured organization and interoperability.
The ontology graph is generated from annotated data sourced from PaveseInImages, PaveseInText, PaveseInWords, and BiblioPavese, through the use of AI algorithms or mappings from XML-TEI to OWL. This process makes it possible to extract information about places, people, characters, organizations, dates, and works.
For example, it becomes possible to situate the author’s writing activity along a timeline or within a georeferenced map by cross-referencing information found in PaveseInText (such as in the letters, diary, poems, etc.) and PaveseInImages, leveraging data visualization tools for educational purposes. This represents a significant advancement over traditional digital scholarly editions, which are typically not semantically structured.
Editorial Criteria and Encoding Model

PaveseInText presents the Digital Scholarly Editions of Pavese’s poetic works (Hard Labor, Death Will Come and Have Your Eyes), major novels (The Harvesters, The Beautiful Summer, Before the Cock Crows, The Moon and the Bonfires), the Dialogues with Leucò, the diary (The Business of Living), and the correspondence, based on existing or forthcoming critical editions.
These editions are structured through the encoding of onomastics, toponyms, direct speech, and—specifically for literary works—authorial corrections. Each edition includes a detailed TEI Header where key metadata are made explicit: for example, information on the date of composition of each poem or novel, revision stages, attribution of responsibility for various aspects of the encoding, bibliographic data, and more.
All textual features are digitally represented using the XML-TEI encoding system, which allows semantic annotation and integration with the OntoPavese ontology.
***
The text encoding model follows the schema defined and maintained by the Text Encoding Initiative (TEI P5, version [G]). It was developed based on the fundamental distinction between creative works and archival documents.
Based on this differentiation:
For archival documents, named entities were encoded using tags such as
<persName>,<placeName>, and<orgName>, while technical terms or obsolete words were annotated using the open-source platform LEAF (see Figure x). The structure of the text and critical notes were added in a second editorial phase using a separate editor. The critical edition’s text was placed inside the<body>of the<text>element, where the structure, named entities, and vocabulary were encoded, along with pointers to notes stored in the<back>section.For creative works, the documentary dimension of manuscripts was represented through multiple
<sourceDoc>elements, each containing one or more<surface>elements corresponding to manuscript pages. Within each surface, individual handwritten lines were encoded using the<line>tag, and editorial interventions were marked using tags such as<del>,<add>,<mod>,<delSpan>, and<anchor>, with attributes specifying the type and location of each intervention.
***
In distinguishing the representation of the text from its presentation through a user interface, the project addressed how to model, already at the encoding stage, the different textual layers: the documentary level and the level of the critical apparatus.
These layers correspond to two distinct editorial models:
a diplomatic edition of the manuscript, and
a critical edition with an apparatus.
To clearly separate these two aspects, each witness of a poem was encoded in a <sourceDoc> using tags for additions, deletions, and substitutions (<add>, <del>, <mod>), while the accepted text of the critical edition was included in the <text> element.
Visualization and TEI Publisher
The visualization of each witness is handled by TEI Publisher—customized and extended to support the display of semantic features and Linked Open Data—which enables the simultaneous consultation of both the digital facsimile of the manuscript pages and the critical text, alongside contextual information about characters, places, organizations, and referenced works.
TEI Publisher is an open-source software widely adopted by the Digital Humanities community. It allows for the creation of scholarly digital editions with maximum flexibility, tailored to the specific textual features of a given corpus—without the constraints of a “one-size-fits-all” framework.
For archival documents, a full-text layout has been designed to provide access to comments and explanatory notes, chronological links to Pavese’s contemporary works, intertextual references, bibliographic citations, and a list of named entities (in the “text and commentary” mode).
For the edition of creative works, additional functionalities have been integrated, including:
a visualization mode that combines facsimile reproductions with diplomatic transcriptions, and
a collation mode, which allows users to compare different versions of a given textual unit side-by-side with the critical edition, in a customizable order.
Project Team Overview
Scientific Coordinators
-
Antonio Sichera (Principal Investigator)
-
Laura Nay (Research Unit Lead)
-
Daria Spampinato (Research Unit Lead)
Project Team
- Adriana Damico
- Angelo Mario Del Grosso
- Laura Mazzagufo
- Giuseppe Palazzolo
- Marina Paino
- Chiara Tavella
- Alberto Luca Zuliani
Research Team
- Attilio Cicchella
- Luca V. Calcagno
- Salvatore Cristofaro
- Miryam Grasso
- Lorenzo Resio
- Andrea Schembari
- Saverio Vita
- Eliana Vitale
Hyperedition Coordinators
- Liborio P. Barbarino
- Christian D’Agata
- Giovanni Gafà
Hyperedition Contributors
- Giuseppe Arena
- Virginia Criscenti
- Valentina Corosaniti
- Giada Di Pino
- Eleonora Gatto
- Fabrizio Lo Presti
- Calogero G. Priolo
- Pietro Sichera