
Il progetto
Introduzione
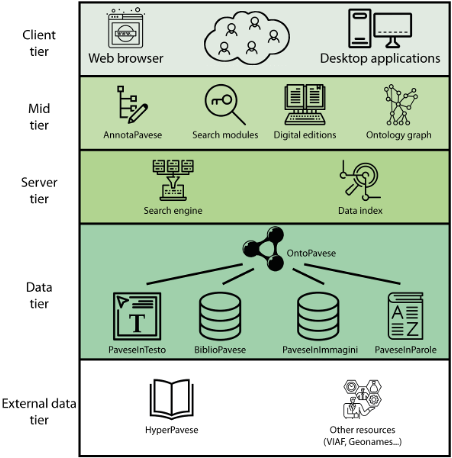
PAVES-e è l’hyperedizione dedicata all’autore di Lavorare stanca e de La luna e i falò: uno spazio digitale integrato dove testi e documenti intessono un dialogo virtuale e virtuoso rivolto a un pubblico vario di lettori, studenti, studio, semplici appassionati.
Il progetto mira allo sviluppo di un’edizione che, nel rispetto dei principi FAIR (Findable, Accessible, Interoperable, Reusable, costruisca un’interfaccia innovativa (a) e integri, attraverso una solida ontologia (b), le dimensioni lessicografiche (e), filologiche (c, d), critiche (g) e didattiche (f ). PAVES-e prevede infatti:
- la progettazione e realizzazione di un’interfaccia web intuitiva e user-friendly (DigitalPavese);
- l’organizzazione delle informazioni e l’integrazione tra le risorse, al fine di sviluppare un’ontologia di luoghi, persone, personaggi, organizzazioni, opere comuni a tutto il patrimonio pavesiano (OntoPavese);
- la realizzazione di un archivio digitale, corredato da descrizioni e metadati, delle immagini di manoscritti autografi, dattiloscritti e prime edizioni (PaveseInImmagini);
- l’elaborazione delle edizioni digitali scientifiche dei romanzi e dell’opera poetica, dell’epistolario e del diario, codificati in XML-TEI e lemmatizzati per quanto riguarda le opere letterarie (PaveseInTesto);
- la creazione di un vocabolario e del relativo software di interrogazione, che comprenda i lemmi delle principali opere pavesiane (PaveseInParole);
- la messa a punto di un tool di annotazione dei testi in XML-TEI – o l’implementazione di un tool già esistente – che ne permetta un agevole riuso in prospettiva didattica (AnnotaPavese);
- la raccolta dell’archivio bibliografico della letteratura secondaria, indicizzata e strutturata e interoperabile (BiblioPavese).
Organizzazione della conoscenza
L’organizzazione semantica della conoscenza del dominio pavesiano è progettata e organizzata in ontologie computazionali. L’ontologia è lo strumento informatico ideale per la gestione dell’eterogeneità semantica, a condizione che i dati che la popolano siano stati adeguatamente catalogati, organizzati in archivi e metadatati. Per consentire l’integrazione e ovviare agli inconvenienti rappresentati dalla forte difformità tra dati eterogenei, è necessario procedere con la normalizzazione dei processi, attraverso l’applicazione degli standard di metadatazione. In particolare, lo schema dell’ontologia viene formalizzato mediante il linguaggio OWL (del W3C), passando attraverso l’apparato logico-deduttivo fornito dalla logica descrittiva SROIQ che sottende OWL. OWL è un linguaggio formalizzato sufficientemente espressivo e potente che consente alle applicazioni software di interfacciarsi autonomamente, rendendo possibile un’efficace elaborazione automatizzata dell’informazione, favorendone e semplificando al contempo l’organizzazione e l’interoperabilità. Il grafo ontologico è creato a partire dai dati annotati opportunamente in PaveseInImmagini, PaveseInTesto, PaveseInParole, BiblioPavese, attraverso anche algoritmi di Intelligenza Artificiale o mapping da XML-TEI a OWL. Verrà dedotta, così, l’informazione sui luoghi, sulle persone, sui personaggi, sulle organizzazioni, sulle date e sulle opere. Sarà quindi possibile, ad esempio, collocare all’interno di una linea del tempo o in una mappa georeferenziata l’attività scrittoria dell’autore, incrociando le informazioni presenti in PaveseInTesto (nell’epistolario, nel diario, nelle poesie, etc.) e in PaveseInImmagini, sfruttando le possibilità della data visualization in funzione didattica: ciò rappresenta un avanzamento rispetto alle edizioni scientifiche digitali di norma non semantiche.
Criteri editoriali
e modello
di codifica

Il modello di codifica del testo segue lo schema definito e promosso dalla Text Encoding Initiative (P5 version [G]) ed è stato sviluppato a partire dalla distinzione fondamentale tra opere creative e documenti d’archivio. A partire da questa differenziazione per i documenti di archivio sono state marcate le entità nominate (<persName>, <placeName>, <orgName>); i termini tecnici o le parole in disuso sulla piattaforma open source LEAF (Figura x), revisionando i testi in un secondo momento per marcarne la struttura e aggiungere le note attraverso un altro editor: il testo dell’edizione critica è stato perciò inserito all’interno del <body> del <text> del documento, codificando la struttura, le entità nominate, il lessico e aggiungendo dei pointer alle note nel <back> del documento. Per le opere creative, inoltre, invece è stata rappresentata la dimensione documentale dei manoscritti è stata rappresentata attraverso differenti <sourceDoc>, ciascuno con una o più <surface> (le carte del manoscritto), all’interno delle quali le righe manoscritte sono state rappresentate attraverso il tag <line> e i fenomeni correttori con <del>, <add>, <mod>, <delSpan>, <anchor> aggiungendo specifici attributi per indicare la posizione e la tipologia dell’intervento, ecc.
Volendo distinguere il momento della rappresentazione del testo da quello della presentazione dei dati attraverso un’interfaccia, ci si è posti il problema su come rendere, innanzitutto nella fase di modellizzazione della codifica, i diversi livelli del testo: quello documentale e quello dell’apparato critico. Tali livelli, infatti, darebbero frutto a due modelli di edizione diversi, l’edizione diplomatica del manoscritto e l’edizione critica con apparato. Per distinguere questi due aspetti si è scelto innanzitutto di rappresentare ciascun testimone di una poesia in <sourceDoc>, attraverso i tag di aggiunta, cassatura, sostituzione (<add>, <del>, <mod>), inserendo invece nel <text> il testo accolto nell’edizione critica.
Visualizzazione e TEIPublisher
TEI Publisher è un software open-source ampiamente utilizzato dalla comunità scientifica delle DH, che consente la creazione di edizioni scientifiche digitali con la massima flessibilità nell’adattamento alle specificità testuali, senza i vincoli di un framework ‘one-size-fits-all’.
In particolare, per i documenti archivistici è stato progettato un layout in full-text che permette di accedere a commenti e note esplicative, connessioni cronologiche con opere contemporanee dell’autore, citazioni intertestuali, riferimenti bibliografici e un elenco di entità nominate (modalità “testo e commento”). Per l’edizione delle opere creative, sono state integrate ulteriori funzionalità, tra cui una modalità di visualizzazione che combina le riproduzioni facsimilari con trascrizioni diplomatiche e una modalità “collazione”, che consente di affiancare e confrontare le diverse redazioni di una stessa unità testuale con l’edizione critica, in un ordine personalizzabile.
Organigramma
Responsabili scientifici
Antonio Sichera (PI), Laura Nay (RU) e Daria Spampinato (RU)
Équipe del progetto
Adriana Damico, Angelo M. Del Grosso, Laura Mazzagufo, Giuseppe Palazzolo, Marina Paino, Chiara Tavella, Alberto L. Zuliani
Équipe di ricerca
Attilio Cicchella, Luca V. Calcagno, Salvatore Cristofaro, Miryam Grasso, Lorenzo Resio, Andrea Schembari, Saverio Vita, Eliana Vitale
Liborio P. Barbarino, Christian D’Agata, Giovanni Gafà
Giuseppe Arena, Virginia Criscenti, Valentina Corosaniti, Giada Di Pino, Fabrizio Lo Presti, Eleonora Gatto, Calogero G. Priolo, Pietro Sichera
